"
"
Mistery solved thanks to Cedrik from OPNsense support :-)
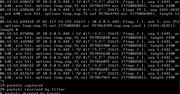
We still had an active IPSec configuration from the very beginning. As this never worked with the remote we changed to Wireguard but forgot the IPSec. As IPSec phase 2 never was established there was no route or interface visible but seems the kernel already "stole" the packets based on phase 1 and then just dropped them. The drop has not been shown in any logfile/packet capture.
So I case of such "weird" issues: ensure you check IPSec settings in GUI as the console does not show routes or interfaces for IPSec if phase 2 is not established. The only trace of this on cli was the output of
We still had an active IPSec configuration from the very beginning. As this never worked with the remote we changed to Wireguard but forgot the IPSec. As IPSec phase 2 never was established there was no route or interface visible but seems the kernel already "stole" the packets based on phase 1 and then just dropped them. The drop has not been shown in any logfile/packet capture.
So I case of such "weird" issues: ensure you check IPSec settings in GUI as the console does not show routes or interfaces for IPSec if phase 2 is not established. The only trace of this on cli was the output of
Code Select
swanctl --list-sas
which finally led us to the right trace