 "
"
no issues here with this version - and IPv4 / IPv6 is monitored constantly, on 2 WAN lines.
This section allows you to view all posts made by this member. Note that you can only see posts made in areas you currently have access to.
#1
24.7, 24.10 Legacy Series / Re: Pings through WAN interface not working (broken in 24.7.1-.3)
August 30, 2024, 12:12:18 PM #2
24.7, 24.10 Legacy Series / Re: Traceroute / ICMP issue after 24.7.1 update
August 23, 2024, 12:58:52 PMQuote from: franco on August 23, 2024, 12:14:43 PM
I plan to work on the code next week to see if we can find it. If anyone will bother to review and accept a potential patch in FreeBSD is the big money question. :)
If you need any testers, I can reproduce the situation here. Feel free to reach out in the topic here.
#3
24.7, 24.10 Legacy Series / Re: Traceroute / ICMP issue after 24.7.1 update
August 23, 2024, 11:50:34 AM
That discussion on the FreeBSD list is wild. People report issues in good faith, and show that reverting the offending code fixes things. At the same time, FreeBSD maintainers are deaf and point to others and just close the topic :o
Probably the easiest is to just not ship kernels with the offending "fixes" and when pfsense hits the same issue, people will probably believe it :-X :o
Probably the easiest is to just not ship kernels with the offending "fixes" and when pfsense hits the same issue, people will probably believe it :-X :o
#4
24.7, 24.10 Legacy Series / Re: clients loosing ipv6 internet now and then
August 21, 2024, 04:24:30 PMQuote from: sjm on August 21, 2024, 02:38:57 PM
@wirehead well, my guess would be that your other IPv6 provider just has different ND settings aka their router is more patient with your neighbor solicitation answers.
Before downgrading to 24.7 kernel I could clearly see my opnsense box having long delays every time when asked for neighbor solicitation, and clearly sometimes the operator's box hit some timeout and I could see short IPv6 outages, until ND worked again.
Well, now I am examining my IPv6 ND traffic with tcpdump and I cannot see any more delays in answering to neighbor solicitation requests! My opnsense is now responding to every ND packet immediately.
So far, it clearly looks like 24.7.1 kernel did break IPv6 neighbor discovery somehow.
Downgrading to 24.7 helped me and the IPv6 shenanigans disappeared. YMMV.
BR, -sjm
Downgraded (opnsense-update -kr 24.7) -> I'll evaluate and see what happens.
edit: no more loss:
#5
24.7, 24.10 Legacy Series / Re: clients loosing ipv6 internet now and then
August 21, 2024, 02:14:15 PM
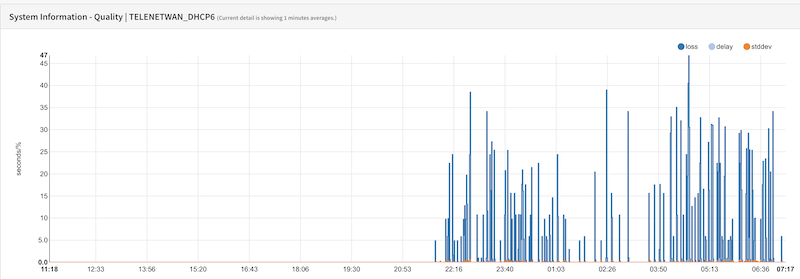
The behavior is strange though, and I'm not sure if it's related to the provider itself. See below graphs (graphs indicating packet loss).
My internet provider for WAN01 (ipv6 - provider: "Telenet") is the same provider as user "cloudz". (This provider was in the local news for having issues with youtube-related issues since "some time" - I wonder if it's related to the loss we see, or if this is related to upstream FreeBSD)

As you can see, this link, has issues, probably (and I use it cautiously) since the upgrade to 24.7.1.
However, at the same time, I also have a WAN02 (also ipv6 - provider: "Proximus"); which doesn't exhibit the behavior.

(these small drops here, are purely from testing..)
My internet provider for WAN01 (ipv6 - provider: "Telenet") is the same provider as user "cloudz". (This provider was in the local news for having issues with youtube-related issues since "some time" - I wonder if it's related to the loss we see, or if this is related to upstream FreeBSD)
As you can see, this link, has issues, probably (and I use it cautiously) since the upgrade to 24.7.1.
However, at the same time, I also have a WAN02 (also ipv6 - provider: "Proximus"); which doesn't exhibit the behavior.
(these small drops here, are purely from testing..)
#6
24.7, 24.10 Legacy Series / Re: clients loosing ipv6 internet now and then
August 21, 2024, 09:31:39 AMQuote from: cloudz on August 21, 2024, 07:28:41 AM
@Franco : Cried victory too fast. Still the same erratic behaviour. I've turned off IPv6 for now.
I see you're using Telenet. I see similar behavior on Telenet, but not on Proximus. Telenet also seemingly issues with Youtube etc (see the news..) - Could be the provider. I'll test "opnsense-update -kr 24.7.2" as well.
#7
24.7, 24.10 Legacy Series / Re: Traceroute / ICMP issue after 24.7.1 update
August 17, 2024, 01:44:09 PM
Ran into gateway monitoring nonsense and I thought I was going insane ;D
-> fixes things beautifully :)
Code Select
opnsense-update -zkr 24.7.1-icmp2
-> fixes things beautifully :)
#8
24.7, 24.10 Legacy Series / Re: LAGG Lan interface not working after upgrade to 24.7 RC2
July 25, 2024, 11:48:10 AM
Awesome - thank you! :)
#9
24.7, 24.10 Legacy Series / Re: LAGG Lan interface not working after upgrade to 24.7 RC2
July 25, 2024, 11:21:23 AMQuote from: franco on July 23, 2024, 11:19:10 AM
In order to be consistent LAGG should advertise it's "native" address under "ether" always and only show "hwaddr" when the user manually overwrote "ether" which is how everything else works. The mechanism is a bit too transparent and/or seems to use what the user would do rather than providing a transient "hwaddr" depending on which member is attached first.
Cheers,
Franco
Hi Franco, sorry to disturb in busy times with the 24.7 release and related upgrade path - but is this fix included in the 24.7 final release? Asking since my main functionality depends on LAGG ;D
#10
24.1, 24.4 Legacy Series / Re: Is IPv6 Dynamic prefix not updating (after losing WAN) still a thing in 24.x?
May 03, 2024, 09:16:12 PM
Ok, but is it the interface -tracking- the WAN, or the WAN not getting a new IPv6?
If you login via SSH to your opnsense appliance when such an event occurs, and you choose option 8 "shell", and then type:
ping -6 google.com (ctrl+c to cancel)
-> Do you get replies?
If yes, it indicates that on the WAN side things would be fine and it's your tracking of the WAN going wrong.
If no, it indicates that it's the WAN not refreshing.
If you login via SSH to your opnsense appliance when such an event occurs, and you choose option 8 "shell", and then type:
ping -6 google.com (ctrl+c to cancel)
-> Do you get replies?
If yes, it indicates that on the WAN side things would be fine and it's your tracking of the WAN going wrong.
If no, it indicates that it's the WAN not refreshing.
#11
24.1, 24.4 Legacy Series / Re: Is IPv6 Dynamic prefix not updating (after losing WAN) still a thing in 24.x?
May 03, 2024, 06:06:09 PM
Technically speaking, ISP's shouldn't be doing dynamic IPv6 prefixes (care to share the ISP?).
That said, is it the interface -tracking- the WAN, or the WAN not getting a new IPv6?
That said, is it the interface -tracking- the WAN, or the WAN not getting a new IPv6?
#12
24.1, 24.4 Legacy Series / Re: IPv6 stops routing a few minutes after boot
April 30, 2024, 07:06:24 PM
Do you have shared forwarding enabled or disabled?
(Firewall -> settings -> advanced)
(Firewall -> settings -> advanced)
#13
24.1, 24.4 Legacy Series / Re: Gateway Recovery - something OPNSense has?
April 24, 2024, 06:34:34 PM
you can do this with the tiered approach for multiwan..
Tier 1: your fast WAN01
Tier 2: your slow, costly WAN02
Set your decision to work on e.g. packetloss / latency -> goes to Tier2 on error condition.
If Tier 1 improves again: switches back.
Edit:just realised, you also want to _kill_ the existing states on WAN02, giving it a hard kick back to WAN01 right? That isn't there.
Tier 1: your fast WAN01
Tier 2: your slow, costly WAN02
Set your decision to work on e.g. packetloss / latency -> goes to Tier2 on error condition.
If Tier 1 improves again: switches back.
Edit:just realised, you also want to _kill_ the existing states on WAN02, giving it a hard kick back to WAN01 right? That isn't there.
#14
24.1, 24.4 Legacy Series / Re: Multi WAN Ipv6 - Load Balancer
April 24, 2024, 04:47:19 PM
In my scenario with dual WAN - I had to keep it enabled - see here:
https://forum.opnsense.org/index.php?topic=39349.msg194153#msg194153
Do note that you will need to NAT IPv6 outgoing over WAN02 for all the prefixes from WAN01 that you might be tracking.
https://forum.opnsense.org/index.php?topic=39349.msg194153#msg194153
Do note that you will need to NAT IPv6 outgoing over WAN02 for all the prefixes from WAN01 that you might be tracking.
#15
24.1, 24.4 Legacy Series / Re: Multi-WAN - IPv6 - IPv6 LoadBalanced Gateway Groups
March 24, 2024, 10:01:17 AM
Hi,
I seem to have found the culprit.
The documentation mentions to -specifically- disable shared forwarding when using multiple gateways with the same Tier:

However, this causes this behaviour where at some point, the OPNsense gateway (for IPv6) starts replying "destination unreachable" to the client.
Multiple issues with this shared/non-shared behaviour have been reported earlier:
https://github.com/opnsense/core/issues/5089
https://github.com/opnsense/core/issues/5094
https://github.com/opnsense/core/issues/5869
In https://github.com/opnsense/core/issues/5869#issuecomment-1611162919 the PR was made to put this note in the documentation, but it seems at some point, this comment has become "inverted". Because Load-Balancing is working now, provided that I do enable shared forwarding. For information, I have also disabled sticky connections, as to have a maximum spread of sessions across WAN links. For specific tools that require fixed Src-IP, you can make a tiered GW group. Enabling/disabling sticky sessions with disabling shared forwarding as recommended still caused the erratic behaviour.
I seem to have found the culprit.
The documentation mentions to -specifically- disable shared forwarding when using multiple gateways with the same Tier:
However, this causes this behaviour where at some point, the OPNsense gateway (for IPv6) starts replying "destination unreachable" to the client.
Multiple issues with this shared/non-shared behaviour have been reported earlier:
https://github.com/opnsense/core/issues/5089
https://github.com/opnsense/core/issues/5094
https://github.com/opnsense/core/issues/5869
In https://github.com/opnsense/core/issues/5869#issuecomment-1611162919 the PR was made to put this note in the documentation, but it seems at some point, this comment has become "inverted". Because Load-Balancing is working now, provided that I do enable shared forwarding. For information, I have also disabled sticky connections, as to have a maximum spread of sessions across WAN links. For specific tools that require fixed Src-IP, you can make a tiered GW group. Enabling/disabling sticky sessions with disabling shared forwarding as recommended still caused the erratic behaviour.

